Vous avez certainement déjà entendu parler du mot OCR, mais vous ne savez peut-être pas comment il peut apporter une valeur ajoutée à votre entreprise. En termes simples, il s’agit de la reconnaissance de texte. Les entreprises utilisent souvent l’OCR pour capturer les données des reçus, extraire les données des documents et lire les plaques d’immatriculation.
Mais qu’est-ce que l’OCR ? L’OCR est une technologie qui évolue constamment et transforme diverses industries en réduisant les processus manuels grâce à l’automatisation. Aujourd’hui, vous pouvez trouver une variété de fournisseurs proposant des logiciels OCR et même des solutions plus avancées telles que le traitement intelligent des documents (IDP). Mais pourquoi cette solution est-elle de plus en plus adoptée par des secteurs tels que la banque, le commerce de détail, les voyages, le secteur juridique et la santé ?
Dans ce blog, vous trouverez tout ce que vous devez savoir sur l’OCR. Nous aborderons ce qu’est l’OCR, son fonctionnement, ses cas d’utilisation, ses avantages et comment vous pouvez vous y mettre. Maintenant, entrons dans le vif du sujet !
Qu’est-ce que la reconnaissance optique de caractères (OCR) ?
La reconnaissance optique de caractères (OCR) est une technologie qui aide les utilisateurs à extraire du texte d’images ou de documents numérisés et à transformer ce texte dans un format lisible par l’ordinateur.
C’est pratique lorsque des données sont nécessaires pour un traitement ultérieur, par exemple pour la comptabilité, la gestion des dépenses, les campagnes de marketing de fidélisation ou la vérification d’identité.
En résumé, vous pouvez réduire les processus manuels de traitement des documents en utilisant le logiciel OCR pour reconnaître les lettres, mots, lignes, phrases et modèles.
Les solutions OCR sont souvent associées à l’intelligence artificielle (IA) et au Machile Learning(ML) pour automatiser certains processus et améliorer la précision de l’extraction des données.
Pour une reconnaissance optimale du texte, il est nécessaire de consacrer du temps et d’entraîner la technologie OCR en l’alimentant avec de nombreuses données. Au fil du temps, elle s’améliore en termes de précision et de couverture de documents.
Maintenant que nous savons ce que c’est, l’étape suivante consiste à vous expliquer comment fonctionne l’OCR.
Comment fonctionne l’OCR ?
L’OCR fonctionne comme la capacité humaine à lire un texte et à reconnaître des modèles et des caractères. Normalement, l’homme lit le texte, puis extrait les informations nécessaires en saisissant manuellement les données dans un système, un fichier de données ou une base de données.
L’OCR procède de manière un peu différente. La technologie améliore la qualité d’un texte ou d’une image scannée et suit plusieurs étapes pour extraire les données qui ont été capturées. La différence est que le travail manuel prend plus de temps et est plus sujet aux erreurs humaines.
Examinons en détail les étapes suivantes du processus d’OCR :
- Étape 1 : prétraitement de l’image
- Étape 2: Segmentation
- Étape 3 : Reconnaissance des caractères
- Étape 4 : Post-traitement de la sortie
Étape 1 : Pré-traitement de l’image
Pour que l’extraction des données soit précise, la qualité de l’image doit être améliorée. Le processus d’amélioration des images est également connu sous le nom de phase de pré-traitement des images. Plus l’image ou le document numérisé est clair et de bonne qualité, plus la sortie de données est précise.
Lors de l’étape de pré-traitement, le moteur OCR recherche automatiquement les erreurs et corrige les problèmes. Les techniques souvent utilisées pour améliorer les images ou les documents numérisés sont les suivantes :
- Redressement – Processus par lequel une photo ou un document numérisé est redressé et l’angle corrigé.

- Binarisation – Processus par lequel une image ou un document numérisé est converti en noir et blanc. La binarisation permet de séparer plus précisément le texte de l’arrière-plan.

- Zonage – Également connu sous le nom d’analyse de la mise en page, utilisé pour identifier les colonnes, les rangées, les blocs, les légendes, les paragraphes, les tableaux et autres éléments.

- Normalisation – Le processus de réduction du bruit en ajustant la valeur de l’intensité des pixels aux valeurs moyennes des pixels environnants.
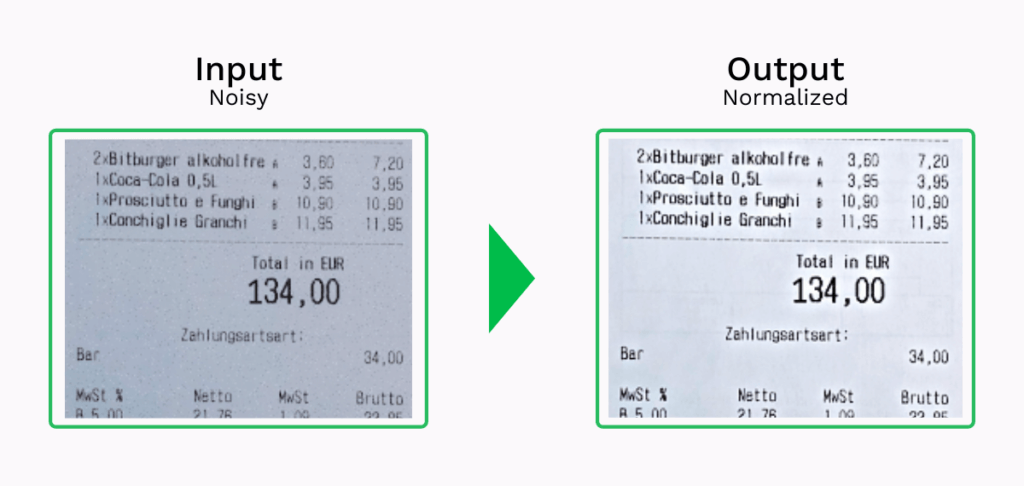
Étape 2 : Segmentation
La segmentation est le processus de reconnaissance d’une ligne de texte à la fois. La segmentation comprend les étapes suivantes :
- Détection des mots et des lignes de texte – Il s’agit de l’identification des lignes de texte et des mots qui leur appartiennent.

- Reconnaissance du script – Processus d’identification du script à partir de documents, de pages, de lignes de texte, de paragraphes, de mots et de caractères.

Étape 3 : Reconnaissance de caractères
Au cours de cette étape, une image ou un document est décomposé en parties, sections ou zones. Une fois la séparation effectuée, les caractères qui s’y trouvent sont reconnus.
Deux approches sont utilisées dans l’étape de reconnaissance des caractères :
- La mise en correspondance de matrices – Le processus dans lequel chaque caractère est comparé à une bibliothèque de matrices de caractères. Le modèle OCR effectue une comparaison pixel par pixel afin d’étiqueter l’image d’un caractère au caractère correspondant.

- Reconnaissance des caractéristiques – Le processus de reconnaissance des modèles de texte et des caractéristiques des caractères à partir d’images. Par exemple, la taille, la hauteur, la forme, les lignes et la structure d’un caractère sont comparées à celles de la bibliothèque existante.
Étape 4 : Post-traitement du résultat
Cette étape concerne les techniques et les algorithmes qui améliorent la précision de l’extraction des données pour un résultat optimal. Tout d’abord, les données sont détectées, puis corrigées si nécessaire.
Les données extraites sont comparées à un vocabulaire ou à une bibliothèque de caractères pour des vérifications grammaticales et des considérations contextuelles afin de compléter la phase de post-traitement.
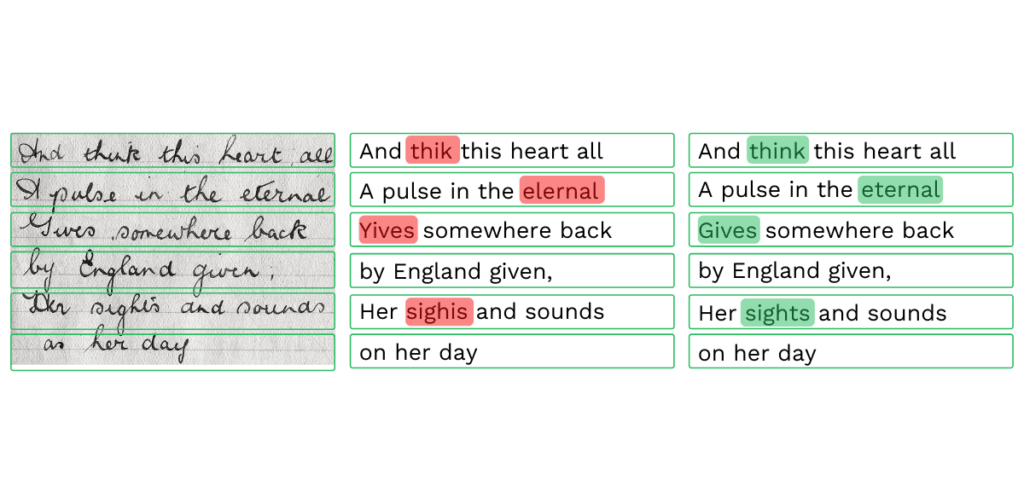
Si l’OCR traditionnelle est exceptionnellement efficace pour convertir des images en texte lisible par une machine et en données précieuses, elle présente également quelques limites. Nous allons maintenant aborder les plus importantes d’entre elles.
Limites de l’OCR basée sur des modèles
L’OCR traditionnelle n’a jamais été conçue comme une solution dynamique d’extraction de données. Elle a été initialement inventée pour les aveugles afin de convertir les caractères imprimés en paroles. Plus tard, cette technologie a été utilisée pour lire et reconnaître du texte noir sur un fond blanc. L’OCR n’est donc pas sans poser quelques problèmes.
Voici les cinq principales limites de l’OCR traditionnelle :
Dépendance à la qualité de l’entrée
La qualité de la reconnaissance et de l’extraction du texte dépend directement de la qualité de l’image fournie au moteur. Par exemple, la précision diminue considérablement lorsque la hauteur des caractères est inférieure à 20 pixels.
Dépendance à l’égard des modèles et des règles
L’OCR traditionnelle nécessite des modèles et des règles pour fonctionner. Des règles strictes doivent être établies en programmant le moteur pour qu’il capture les données dans les champs et les lignes appropriés. Par conséquent, elle ne peut pas faire face à la diversité des documents et a du mal à traiter les documents non structurés.
Manque d’automatisation
En raison de sa dépendance à l’égard des modèles et des règles, l’OCR traditionnelle manque de nombreuses possibilités d’automatisation. Par exemple, si vous souhaitez extraire des données structurées des factures, chaque champ de données spécifique nécessitera une nouvelle règle. Et comme vous le savez, les factures se présentent sous différents styles et formats, ce qui entraîne de très nombreuses règles.
L’ajout de règles supplémentaires entraînerait une augmentation des données et des ressources nécessaires à la formation du moteur d’OCR. Avec l’approche conventionnelle, il y aura toujours plus de règles à mettre en place, ce qui peut devenir un sérieux goulot d’étranglement.
Coûteux
Comme il faut développer davantage de règles et d’algorithmes pour augmenter la précision, l’OCR traditionnelle peut devenir très coûteux. En outre, la création de ces règles et algorithmes ne garantit pas toujours un résultat de haute qualité, car elle dépend également de la qualité de l’image en entrée.
Mauvaise adaptation à une grande variété de documents
Avec l’OCR traditionnelle, le résultat est souvent très précis lorsque les documents sont simples et comportent peu de variations. Cependant, de nombreuses entreprises doivent traiter des documents variés dans le cadre de leurs flux de travail.
Plus la variété des documents est grande, plus la tâche devient difficile. Le moteur d’OCR traditionnel étant entraîné à l’aide de modèles, il ne peut pas faire face à une grande variété de documents.
En résumé, nous pouvons conclure que l’OCR traditionnelle n’est pas parfaite. Mais ne vous laissez pas décourager. Le marché devenant chaque année plus exigeant en termes de besoins et de fonctionnalités, l’OCR a fait de nombreux bonds en avant pour répondre à cette demande.
Jetons un coup d’œil à une technologie d’OCR plus avancée.
La nouvelle génération de la technologie OCR
La prochaine génération de technologie d’OCR est déjà là. Elle est souvent alimentée à la fois par l’apprentissage automatique et l’IA, ce qui permet aux organisations de réaliser ce qu’elles ne pouvaient pas faire avec l’OCR basé sur des modèles : l’automatisation. Cette technologie révolutionnaire est également connue sous le nom de traitement intelligent des documents (IDP).
L’IDP peut fournir des résultats dépassant les capacités humaines lorsque l’efficacité et le temps sont pris en compte. Il donne un sens aux données, les catégorise, les organise et les convertit automatiquement pour l’utilisateur, le tout en quelques secondes.
L’une des principales avancées réside dans le fait qu’il n’est pas limité à des modèles ou à des règles comme son prédécesseur conventionnel. Cela rend ce logiciel OCR alimenté par l’IA plus évolutif et plus abordable pour les entreprises.
Examinons de plus près les rôles de l’apprentissage automatique et de l’IA dans les solutions OCR modernes.
L’approche du machine learning
Les logiciels OCR intégrant l’apprentissage automatique (ML) peuvent être entraînés à reconnaître des modèles et la signification du contenu par le biais d’un ensemble de règles. Cela peut se faire par le biais de l’apprentissage supervisé, de l’apprentissage non supervisé ou en combinant ces deux méthodes de formation.
Nous allons maintenant expliquer ces méthodes à l’aide d’un exemple (nous essaierons de le rendre aussi simple que possible).
Apprentissage supervisé
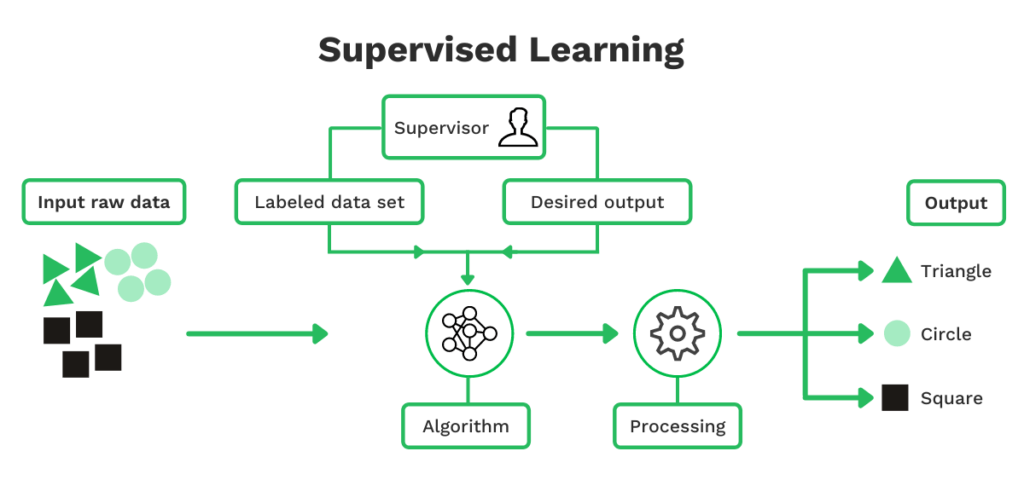
L’apprentissage supervisé en ML fait référence à l’utilisation d’ensembles de données étiquetées pour former des algorithmes qui classent les données et prédisent les résultats avec une grande précision. Pour y parvenir, le modèle doit être alimenté par une grande quantité de données d’entrée.
Par exemple, si vous souhaitez prédire si un e-mail est un spam et le classer dans une catégorie, vous devez alimenter le moteur avec suffisamment de spams. Avec suffisamment de données, le modèle peut reconnaître et prédire la catégorie et ainsi classer correctement un courriel.
Une approche similaire s’applique à la prédiction de l’emplacement du prix des articles ou du nom du commerçant sur les reçus.
Apprentissage non supervisé
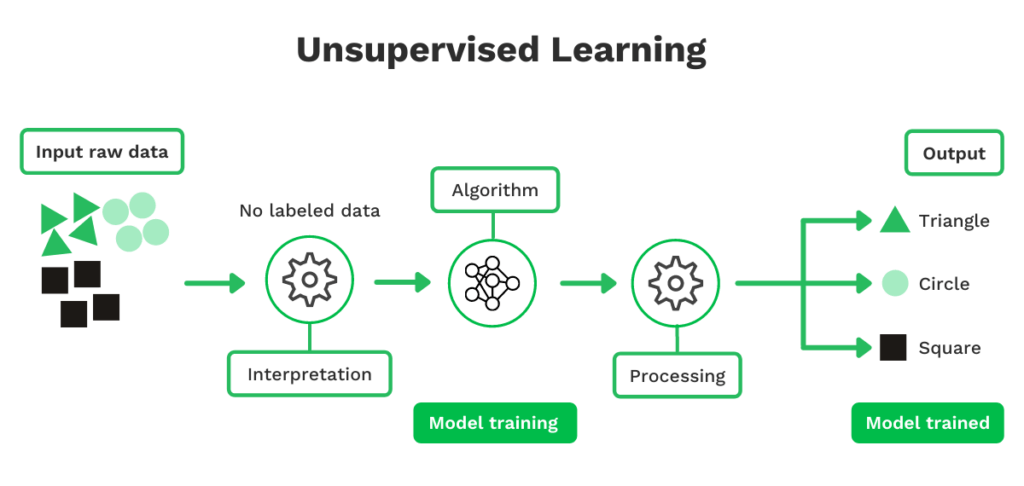
L’apprentissage non supervisé est, par essence, similaire à l’apprentissage supervisé. La différence est que l’apprentissage non supervisé utilise des données non étiquetées au lieu de données étiquetées. Cette approche est plus utile lorsque les propriétés communes sont difficiles à identifier dans un ensemble de données, ce qui donne plus de liberté au modèle.
Même si les étiquettes des points de données ne sont pas définies, les points de données réels restent. Par conséquent, le modèle peut reconnaître des modèles en observant les données d’entrée. En termes simples, l’apprentissage non supervisé peut reproduire les capacités humaines d’adaptation et d’apprentissage.
Par exemple, si votre entreprise doit traiter des reçus, vous devrez alimenter le modèle d’apprentissage non supervisé avec de nombreux reçus. Le modèle d’apprentissage automatique interprète alors les données d’entrée et fait des interprétations de similitudes.
Disons qu’il est capable de définir le nom du commerçant et le montant total (c’est-à-dire les points de données) autour de l’emplacement exact sur les reçus. Le modèle utilise ensuite ces informations pour prédire si le document suivant est un reçu ou non, en fonction des similarités.
Apprentissage semi-supervisé
Comme son nom l’indique, les données d’entrée sont à la fois étiquetées et non étiquetées dans l’apprentissage semi-supervisé. Il est souvent utilisé pour résoudre les problèmes d’extraction de données lorsque l’on traite de gros volumes de données.
Comme l’apprentissage semi-supervisé combine le meilleur des deux, il permet de relever les défis des deux approches : classification, temps, coûts et volumes élevés de données.
Il est idéalement utilisé dans les cas où un petit nombre de données d’apprentissage peut apporter des résultats notables en termes de précision (par exemple, la classification de documents d’identité).
Comment savoir quelle approche d’apprentissage automatique choisir ? La réponse est simple : vous n’en avez pas besoin. D’autant plus que de nombreux fournisseurs proposent des solutions OCR prêtes à l’emploi. Maintenant que le rôle de l’apprentissage automatique est expliqué, nous allons aborder le rôle de l’IA.
L’IA pour l’automatisation
Avec l’IA intégrée au logiciel OCR, la solution peut s’adapter et apprendre en permanence à reconnaître les données avec plus de précision. Elle peut créer une compréhension profonde de la sémantique et élargir la gamme des langues, formats, mises en page et types de documents pris en charge.
L’IA permet au logiciel ou au système OCR d’analyser toutes les données disponibles, de trouver des corrélations et de créer une base de connaissances riche en informations. La base de connaissances créée par l’IA peut s’adapter au fil du temps, ce qui peut contribuer à la progression de la précision de l’extraction des données.
La meilleure partie de l’IA est qu’elle reproduit les capacités humaines pour analyser et comprendre les informations clés avec une vitesse et une précision élevées.
Quelle que soit votre activité, une solution OCR alimentée par l’IA peut vous aider à faire travailler les données pour vous.
Puisque nous avons couvert le ML et l’AI, examinons les avantages lorsque les deux sont intégrés dans la solution OCR.
Avantages au-delà de l’OCR classique
Au-delà de la reconnaissance conventionnelle des caractères, les solutions OCR avancées peuvent faire beaucoup plus. Pour vous donner une idée de l’avantage qu’il y a à utiliser cette technologie dans votre flux de traitement des documents, nous avons dressé la liste des avantages suivants :
Numériser des documents en quelques secondes – Grâce au logiciel OCR, votre entreprise peut se passer de papier et faire extraire les informations des documents dans un format numérisé tel que PDF, JSON, CSV, XML, etc. Ce processus peut être réalisé en quelques secondes.
Temps de mise en œuvre plus rapide – Les solutions OCR plus avancées ne reposent pas uniquement sur des règles et des modèles. Il faut donc moins de temps pour former le moteur et mettre en œuvre la technologie.
Évolutivité – La nouvelle génération de solutions OCR en nuage offre une évolutivité que son prédécesseur conventionnel n’a pas réussi à atteindre. S’il est possible de faire évoluer l’OCR basée sur des modèles, cela peut rapidement devenir trop coûteux pour les entreprises.
Une plus grande précision – Alors que l’OCR classique a une précision d’extraction des données de 60 à 85 %, de nombreuses solutions plus avancées intégrant l’IA et machine learning peuvent atteindre 99 %. Si l’extraction manuelle des données offre une précision de 90 à 95 %, elle est beaucoup plus lente et inefficace pour de nombreuses entreprises.
Réduction des erreurs de saisie manuelle – Les erreurs se produisent souvent lorsque les gens travaillent sur des tâches fastidieuses et répétitives, comme la saisie manuelle de données. L’OCR automatise ces tâches, réduisant ainsi les erreurs humaines et les erreurs de saisie manuelle des données. Avec l’IA et le machine learning, le taux d’erreur est donc davantage réduit.
Délai d’exécution plus rapide – Les flux de travail traditionnels de traitement des documents comportent souvent de nombreuses tâches lentes et lourdes qui créent des goulots d’étranglement coûteux. La vérification et l’extraction manuelles des données peuvent prendre 10 à 20 minutes par document, alors que l’OCR traditionnelle peut le faire en moins de la moitié du temps. L’IDP, en revanche, peut le faire en 15 secondes, ce qui équivaut à 98 % du temps gagné.
Réduction des coûts – Comme l’OCR alimentée par l’IA permet des délais d’exécution plus rapides, automatise les tâches fastidieuses et minimise les erreurs de saisie de données, les frais généraux sont considérablement réduits. Cela nous amène à l’un des principaux avantages pour les organisations : la réduction des coûts. Avec le traitement manuel des documents, le coût par document peut varier entre 4 et 6 euros. L’OCR traditionnelle peut réduire le coût par document à 1-2 € et l’IDP à moins de 0,50 €.
Détection des fraudes – Chaque année, les entreprises perdent des sommes considérables à cause de la fraude documentaire. L’OCR plus avancée peut aider à résoudre ce problème grâce à la détection des fraudes par l’analyse des images et des données EXIF. Elle peut vous éviter de perdre des capitaux à cause de la fraude interne et externe.
Amélioration de l’expérience client – Il existe de nombreux cas où l’OCR intégrée à l’IA permet d’améliorer l’expérience client. Par exemple, lorsque les banques enregistrent de nouveaux clients, la technologie rend le processus d’embarquement plus fluide et plus agile grâce à l’intégration mobile.
Comparaison entre les méthodes de traitement des documents
Nous avons couvert les multiples avantages de la nouvelle génération de technologies OCR. Mais il existe encore un large éventail de méthodes et de solutions différentes pour traiter les documents, et il peut être difficile de trouver la bonne. Pour vous faciliter la vie, nous avons créé un tableau comparatif des différentes méthodes.

En conclusion, la technologie OCR apporte de nombreux avantages aux entreprises. Cependant, les technologies plus avancées, telles que la PDI, sont bien plus performantes que les solutions traditionnelles. Bien sûr, aucune solution n’est parfaite, c’est pourquoi la technologie OCR s’améliore constamment pour surmonter certaines limites.
Maintenant que nous avons couvert les principaux avantages, il est temps de passer en revue certains des cas d’utilisation les plus courants.
À quoi sert l’OCR ?
Par défaut, toute tâche répétitive à fort volume qui inclut le traitement de documents peut être automatisée grâce à un logiciel OCR alimenté par l’IA. Nous allons mettre en évidence quelques cas d’utilisation ci-dessous pour vous inspirer à commencer à utiliser une solution OCR pour des procédures similaires au sein de votre organisation :
- OCR de reçus pour les programmes de fidélité
- Extraction de données à partir d’identifiants pour l’accueil des clients
- Traitement automatisé des factures pour les comptes fournisseurs
- Automatisation des contrôles de complétude des documents
OCR de reçus pour les programmes de fidélisation
Les programmes de fidélisation existent sous de nombreuses formes et tailles. La plupart d’entre eux impliquent une sorte de campagne à base de points ou de promotion de cashback. Les clients doivent envoyer leur reçu au détaillant et, en retour, ils reçoivent une récompense pour avoir acheté le produit.
Comme vous pouvez l’imaginer, ces programmes impliquent généralement beaucoup de travail administratif, car il faut vérifier les preuves d’achat (reçus, factures, etc.), mettre à jour la base de données des clients et déterminer et accorder les points de fidélité ou le cashback.
Dans ce cas, l’OCR des reçus via une solution de numérisation est optimale pour prendre en charge les tâches de back-office fastidieuses et sujettes aux erreurs.
Les organisations qui doivent vérifier si les consommateurs ont effectivement acheté les produits de la campagne de fidélité n’ont plus besoin de vérifier les reçus manuellement. L’OCR peut scanner les lignes des reçus et vérifier si les produits ont été apportés pendant la période de la campagne.
Champs de données qui peuvent être extraits :
- Langue de réception
- Pays d’origine
- Nom du commerçant
- Mode de paiement
- Montants et pourcentages de la TVA
- Devise
- Montant total
- Date d’achat
- Articles de ligne
- Et bien d’autres champs encore
Certains fournisseurs d’OCR, comme Klippa, peuvent également aider les organisations à prévenir la fraude en fournissant une détection des doublons basée sur le hachage des images. Grâce à la détection précoce des tentatives de fraude, les pertes de temps et d’argent sont minimisées.
Extraction de données à partir d’identifiants pour l’accueil des clients
Les organisations du secteur financier, telles que les banques, doivent vérifier l’identité de leurs clients pour s’assurer qu’ils sont bien ceux qu’ils prétendent être lors de l’accueil des clients.
Ce processus est également connu sous le nom de processus de connaissance du client (KYC). Vérifier l’identité des clients et saisir manuellement les données dans plusieurs systèmes pour une validation croisée peut être inefficace et prendre beaucoup de temps.
C’est pourquoi l’OCR est utilisée dans ce processus : pour accélérer le temps de traitement et augmenter le nombre de nouveaux clients. Grâce au logiciel OCR, les institutions financières peuvent simplement scanner et extraire automatiquement les données des pièces d’identité en quelques secondes.
Les champs de données qui peuvent être extraits :
- Nom complet
- Nationalité
- Date de naissance
- Date & lieu de délivrance
- Période de validité
- Numéro de document
- Zone lisible par machine (MRZ)
- Autres champs
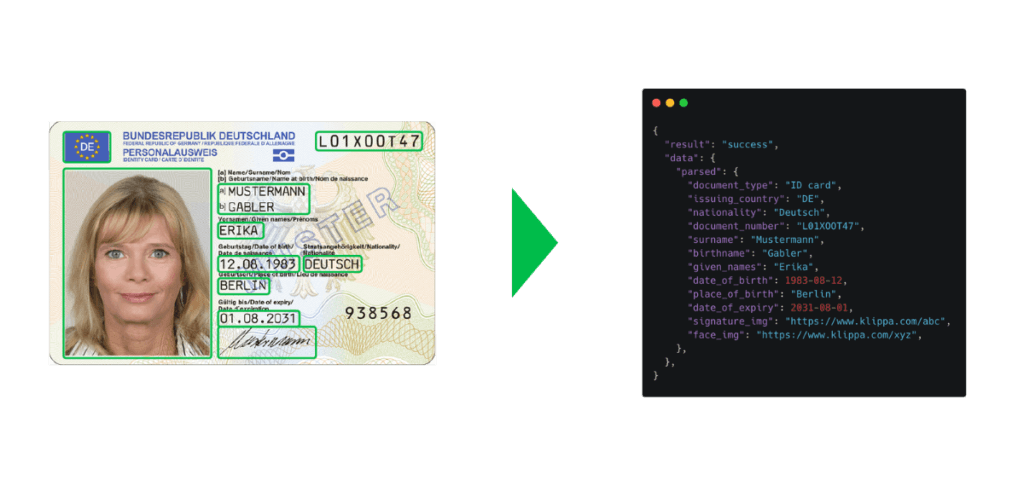
Une fois les données extraites, elles peuvent également être recoupées avec des bases de données sur les fraudes ou des listes noires pour découvrir les tentatives de fraude.
La technologie OCR est fortement intégrée dans l’automatisation KYC de nos jours, alors que la majorité de l’embarquement des clients se fait de manière numérique. La vidéo ci-dessous visualise un tel processus.
Traitement automatisé des factures pour les comptes fournisseurs
Le service des comptes fournisseurs d’une entreprise approuve les factures avant qu’elles ne soient payées. Ce processus peut être redoutable. Les factures qui arrivent doivent être organisées, vérifiées, corrigées, approuvées par la bonne personne, payées et enfin ajoutées au système comptable de l’entreprise.
Grâce à la technologie OCR, les entreprises peuvent rationaliser et automatiser leur flux de travail de comptabilité fournisseurs et éliminer les tâches manuelles en capturant automatiquement les données des factures. Il vous suffit d’alimenter le logiciel avec les factures, et il s’occupe du reste : de la numérisation à l’envoi du résultat final à votre système de planification des ressources de l’entreprise (ERP) ou de comptabilité.
Un rapport de MineralTree indique que 64 % des organisations qui ont automatisé leurs comptes fournisseurs traitent plus de factures que celles qui ne l’ont pas fait, et que 23 % traitent le même nombre de factures avec moins de personnel.
Nous avons trouvé des chiffres similaires dans nos recherches internes. En automatisant le traitement des factures pour les comptes fournisseurs, vous réduisez le temps passé jusqu’à 70 %, le délai d’exécution de plusieurs jours à quelques minutes, vous minimisez les erreurs et vous réalisez des économies de plus de 70 %.
Automatisation des contrôles de complétude des documents
Dans des secteurs tels que le droit et la banque, le personnel consacre beaucoup de temps à vérifier la complétude des documents pour s’assurer qu’ils contiennent les informations requises. Par exemple, un contrat juridiquement contraignant doit contenir les signatures des parties qui concluent l’accord.

L’échec de la vérification de la complétude peut avoir de graves conséquences et entraîner des amendes. Sans les signatures des deux parties, par exemple, un contrat se transforme en un tas de papiers inutiles, et est inapplicable par la loi.
C’est là que l’OCR entre en jeu. Elle se charge de vérifier la complétude et de valider l’originalité d’un document. Il peut détecter en quelques secondes si des signatures sont apposées sur un document et/ou si certaines informations cruciales, comme une clause importante, sont manquantes.
Pour vous donner une vue d’ensemble, les fournisseurs d’OCR tels que Klippa peuvent automatiser les tâches suivantes de vérification de la complétude :
- Examiner le nombre de documents
- Classifier le type de document
- Identifier le nombre de pages par document
- Valider la présence de champs, de valeurs, de lignes ou de composants spécifiques (par exemple, des signatures, des images)
- Recouper les données entre les documents avec une base de données externe ou interne
On peut conclure que l’OCR peut être utilisée à de nombreuses fins et dans de nombreux cas. Cela vous a-t-il incité à rechercher des possibilités d’automatisation au sein de votre organisation ? Alors la dernière question est de savoir comment commencer. Pour vous aider, nous allons aborder dans la prochaine section les différentes manières d’intégrer la technologie OCR dans vos opérations.
Comment commencer à intégrer l’OCR ?
Plusieurs éléments sont à prendre en compte lorsque vous envisagez d’intégrer l’OCR dans votre entreprise. Ces facteurs peuvent être le type de document, le volume de traitement de documents par mois, les ressources de votre organisation, votre cas d’utilisation, etc.
Pour vous aider, nous avons répertorié les options suivantes :
- Intégration avec l’API OCR
- Solution de numérisation mobile
- Solution de bout en bout
Intégration avec l’API OCR
L’intégration avec l’API OCR vous permet de traiter des documents en les envoyant par le biais d’une application mobile, d’un e-mail et d’une application Web. Il s’agit souvent du meilleur choix si vous avez déjà un logiciel ou une application existante dans laquelle vous souhaitez intégrer la technologie OCR.
L’interface de programmation d’applications (API) permet à votre logiciel ou à votre application de communiquer avec le fournisseur d’OCR et d’utiliser sa technologie pour le traitement de vos documents.
Bien que cela puisse sembler compliqué, vous pouvez récupérer les données des documents dans un format structuré en quelques secondes.
Solution de numérisation mobile
Les solutions de numérisation mobile, comme leur nom l’indique, prennent en charge les cas d’utilisation où les organisations ont besoin d’un moyen agile de capturer des données. Par exemple, vos employés n’ont pas besoin de stocker physiquement les reçus car ils peuvent en prendre une photo.
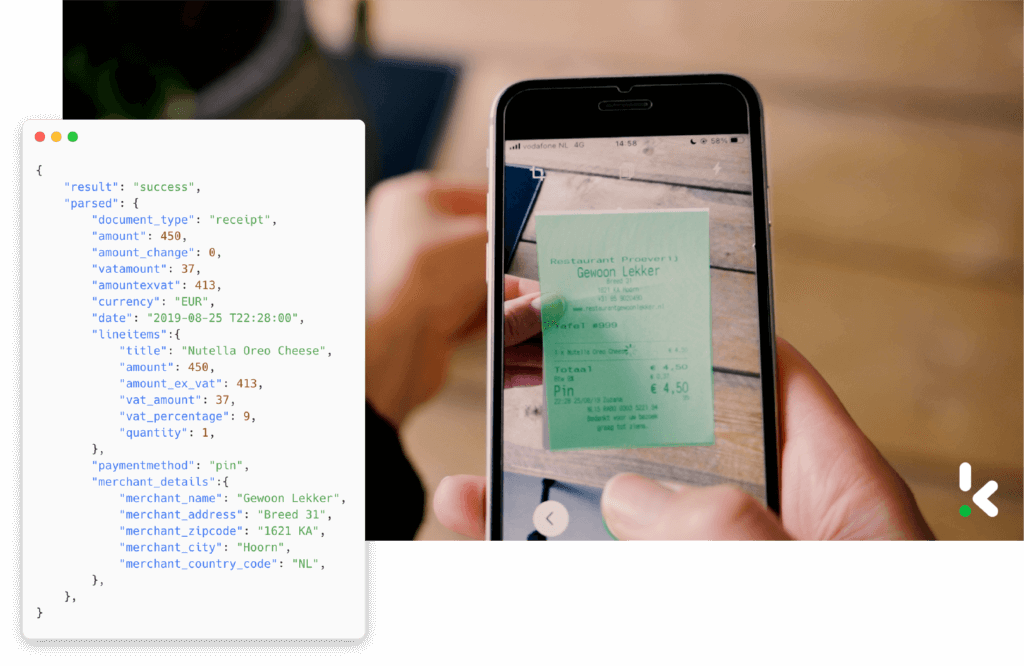
Le processus consistant à retourner au bureau avec les reçus pour créer un remboursement peut être éliminé. Cela permet bien sûr de gagner du temps et de réduire les frais généraux.
Pour intégrer la solution de numérisation mobile, vous avez besoin d’un kit de développement logiciel (SDK) correctement documenté.
Il est très personnalisable et, grâce aux fonctions de prétraitement d’image de haute qualité, vous pouvez numériser des documents ou même des objets tels que des compteurs électriques dans des conditions difficiles.
Un SDK est le meilleur choix si vous avez besoin d’utiliser une solution OCR alimentée par l’IA dans votre application mobile. En revanche, une API est plus adaptée si vous souhaitez simplement télécharger des documents via un portail ou une application Web au lieu de les numériser avec un appareil mobile.
Solution de bout en bout
Avec une solution de bout en bout, vous pouvez démarrer relativement facilement et rapidement. Il vous suffit de trouver un fournisseur de logiciel OCR capable de vous aider à réaliser votre projet.
Par exemple, une solution de bout en bout comme Klippa DocHorizon peut aider les entreprises à rationaliser tous les flux de traitement des documents. Ses technologies de pointe peuvent automatiser l’extraction, la classification, la conversion, l’anonymisation et la vérification des données.
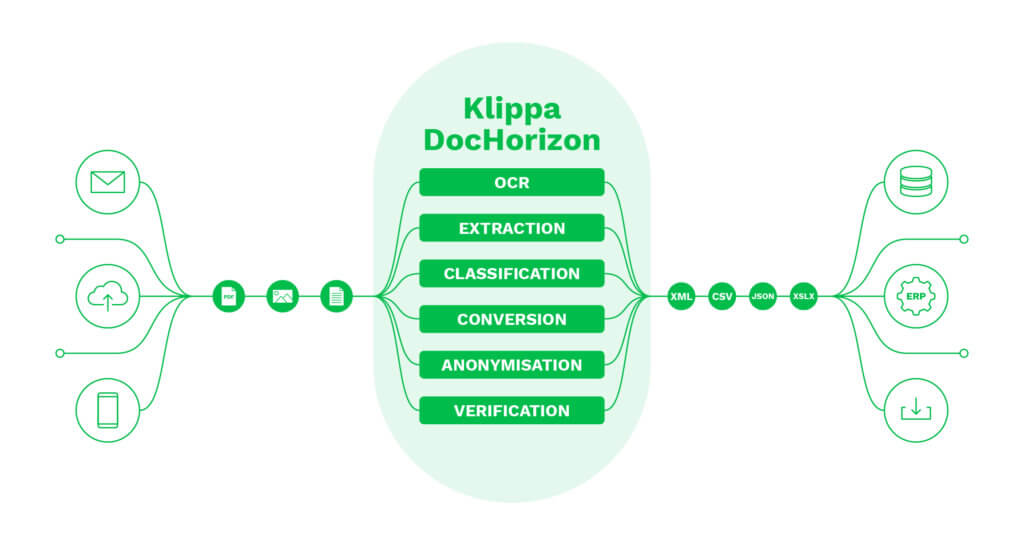
Aller au-delà de l’OCR traditionnel avec Klippa
L’OCR traditionnel devient plus obsolète que jamais. Les entreprises doivent trouver un moyen d’améliorer leurs résultats, de renforcer l’expérience client et, en même temps, d’intégrer des outils pour accroître l’efficacité de l’organisation.
C’est là que Klippa peut vous aider. Que vous souhaitiez intégrer la technologie OCR par le biais d’une API, d’un SDK, ou que vous souhaitiez simplement démarrer immédiatement avec une solution de bout en bout, Klippa peut tout faire.
Associez-vous à Klippa pour faire de vos employés les champions du traitement des documents. Commencez en remplissant le formulaire de démonstration ci-dessous !